问题以及准备
问题
break的使用:A “break” statement terminates execution of the innermost “for”, “switch”, or “select” statement within the same function.也就是说break不仅仅用于for
所以导致爬虫代码未能正确的结束,修改后的代码如下
这里明确跳出位置来实现代码。还有就是上面提到的知乎禁止的问题,我在写爬虫的时候并没有模拟登陆也没有实现代理功能(当然爬虫本身应该提供代理相关的实现来避免触发网站的防御,暂时不会写,所以…),因为也没这个需求,我之所以写这个是看到it推送文章,里面有用python,java写知乎爬虫,然后说是看看知乎妹纸占多少,然后没有看到go的,所以我就简单写了一个 = =。其实很简单,就是http.Get()方法的使用以及简单的调度,写的很匆忙,所以可能会比较混乱。

仅仅200多条数据就这样了…此时只有登陆后才能正确访问(因为账户安全方面,我没有模拟登陆)。
准备
大部分是使用的golang基础包。但是为了分析html以及解析复杂json,所以需要get以下package:
- github.com/bitly/go-simplejson
- github.com/PuerkitoBio/goquery
爬虫调度
|
|
这里显示定义了爬虫需要的一些基本方法。其中保存数据的时候我只保存了用户本身的数据,存在mysql数据库中,而与之关联的教育背景,工作经历我只有简单的log,并没有存入数据库(毕竟我只是来看妹子的占比或者说互联网行业的占比)。其中sql部分我也有放入代码里。而调度部分就如在break部分贴出的代码中写的那样,首先查看url池子里有没有未爬取的url,有的话就尝试获取spider实例进行爬取,没有则阻塞等待。反之,如果url池子已经空了,则观察爬虫池子是不是已经充满,即所有的爬虫已经完成工作,没有则等待其完成,当然这时候基本会有新的待爬取url进入url池子,除非http请求失败了。如果url池子是空的,所有爬虫实例也已经归还的话则break,爬虫结束。
所以说正常情况下爬虫肯可能跑很久很久,所以这里实现了人为退出爬虫的方法:
|
|
这里等待监视用户输入信号比如用户ctrl+c。这时候系统会发现该信号并将其写入名为stopFlag的channel中,此时将会跳出for循环,执行Stop方法:
这时候系统会去检查爬虫池子(此时就算url池子中有未爬取的url也不会进行分配了),直到所有的爬虫实例归还为止,然后退出系统。这样既可以实现人为停止爬虫也保证每个爬虫实例执行过程的完整,不会出现一些破损流程。
还有一点就是关于错误以及panic的处理,在具体的爬虫代码中不会很仔细的检查这些错误,panic就panic了。会在调度里检查这些情况,因为这些错误是无关紧要的,甚至某些情况下遇到error我会主动panic(这是不可避免的,比如我用simpleJson解析json在遍历节点的时候会出现nil的情况,这里我直接忽略错误或者主动panic,当然这里还有多种选择,我的选择是直接放弃这条url的解析,抛弃数据哪怕已经解析了大部分的数据,当然也可以只是跳过这一步,将剩余的数据保存,这些只需要在recover逻辑里写清即可),因为在爬虫实例执行过程中我并不会特别关心某个协程的执行情况,出错了我就将其归还即可,等待下一轮的调度,所以在调度里会有这样的代码,其中去重工作我是交给数据库自己实现的,即报错就跳过该数据。
好了,这大概就是爬虫的执行过程了,详细的代码不过是Get请求,然后使用goquery/simpleJson获取我们想要的数据。具体的使用方法他们都有提供相应的doc。此处就不多加赘述。
运行截图

这里就是一位陈小伊的用户 描述写的是非典型理科女 行业是科研 女性(0是男性,1是女性,2是不知道),清华大学神经科学,至于工作履历没写,现居美国。可以通过知乎连接people/chen-xiao-yi-76-92进入其页面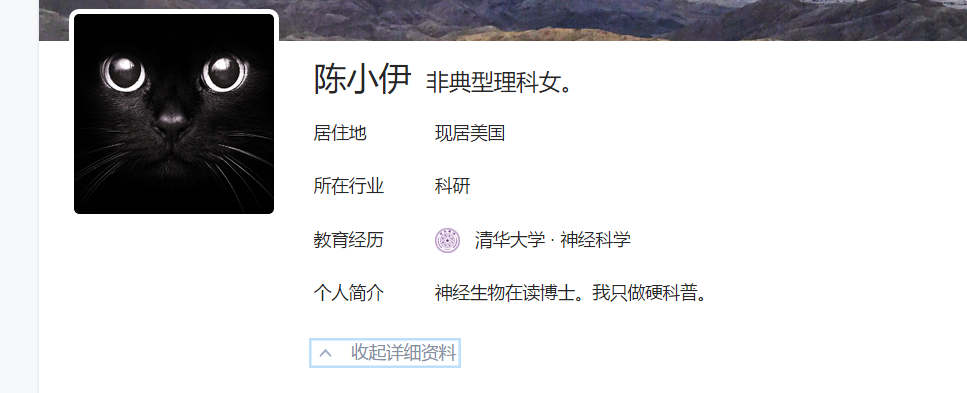

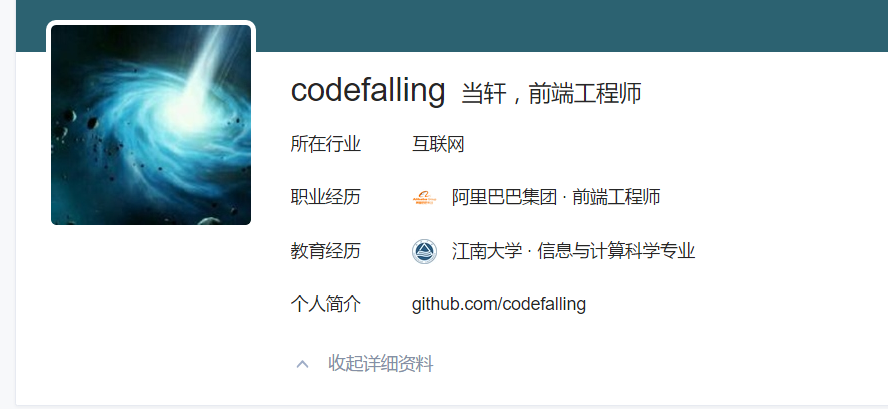
上面的同理
还有结果,大概一个多小时获取了219条数据,公司网慢的很。
然后妹子是78位,感觉比例还是可以的啊~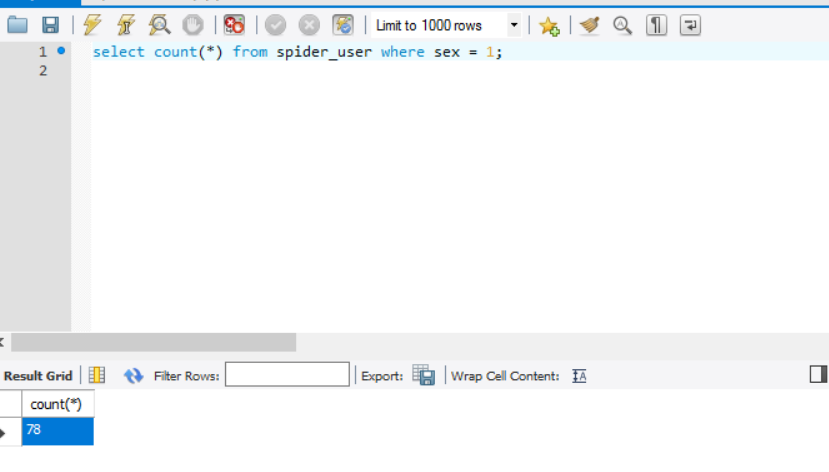
打印end处是因为按下ctrl+c,此时显示等待运行中的爬虫结束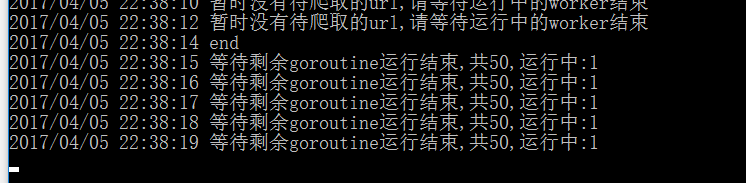
代码在github里
